Principle
Generally speaking, data in Pegasus is stored with 3 replicas. For each partition, under normal situation, there should be one primary replica and two secondary replicas, totaling three replicas providing service.
However, node failures, network issues, and heartbeat loss are inevitable in a cluster, leading to replica loss and affecting service availability. Pegasus has three detection mechanisms to identify replica loss:
-
2PC timeout: Mainly ensures the health of the primary-secondary replica relationship. This is a replica-level failure detection, triggered each time a write enters the 2PC phase.
-
failure_detect: Uses a lease mechanism to ensure the connectivity between the meta server and replica server. This is a server-level failure detection mechanism that can quickly identify a node’s availability issue. The default interval in production is 3 seconds.
-
group_check: A task initiated when a replica becomes the primary. It periodically sends RPCs to secondaries to check their liveness. The default interval in production is 100 seconds.
Among them, 2PC timeout and group_check help the primary detect connection issues with its secondaries and remove faulty replicas from the topology, reporting them to meta server. failure_detect helps the meta server identify faulty replica nodes and remove all their replicas from the topology.
Through these three detection mechanisms, the meta server detects lost replicas and triggers the subsequent cure process to restore all replicas to a healthy state. The degree of replica loss affects the ability to read and write (introduced in Load Balancing as well):
- One primary and two replicas are available: The partition is completely healthy and can read and write normally.
- One primary and one replica are available: According to the PacificA consistency protocol, it can still read and write safely.
- Only one primary is available: At this point, it is not writable, but readable.
- All are unavailable: At this point, it is neither readable nor writable. This situation is referred to as DDD, which stands for Dead-Dead-Dead, indicating that all three replicas are unavailable.
In the above situations, except for the completely unavailable DDD state, MetaServer can automatically replenish replicas and eventually restore to a completely healthy state. However, if a partition enters the DDD state, MetaServer cannot automatically recover it and manual intervention is required.
This discussion provides examples of entering the DDD state. In fact, as long as a partition enters the DDD state and one of the last two nodes in LastDrop cannot start normally, it will enter the DDD state requiring manual intervention. During the process of multiple nodes starting and stopping in an online cluster, this situation is quite common.
The health status can be viewed using the ls -d command in the Shell tool. If the number of read_unhealthy is greater than 0, it indicates that a partition has entered the DDD state.
DDD Diagnostic Tool
Starting from version v1.11.0, Pegasus has provided the ddd_diagnose command in the Shell tool to support automatic DDD diagnostics.
Command usage:
ddd_diagnose [-g|--gpid appid|appid.pidx] [-d|--diagnose] [-a|--auto_diagnose]
[-s|--skip_prompt] [-o|--output file_name]
Parameter explanation:
-
-g: Specify the app_id or partition_id, for example,-g 1or-g 1.3; if not specified, the operation is performed on all tables. -
-d: Enter diagnostic mode; if not specified, only the DDD situation is displayed without diagnosis. -
-a: Enable automatic diagnosis, that is, if the diagnostic tool can find a suitable backup as the primary backup for this partition while ensuring data consistency, it automatically sets it as primary to complete data recovery without manual intervention. -
-s: Avoid interactive mode; if not specified, the diagnostic process may require user input to complete selections, confirmations, or information supplementation. -
-o: Output the results to a specified file.
Usage example (if not clear, please open the image in a separate page):
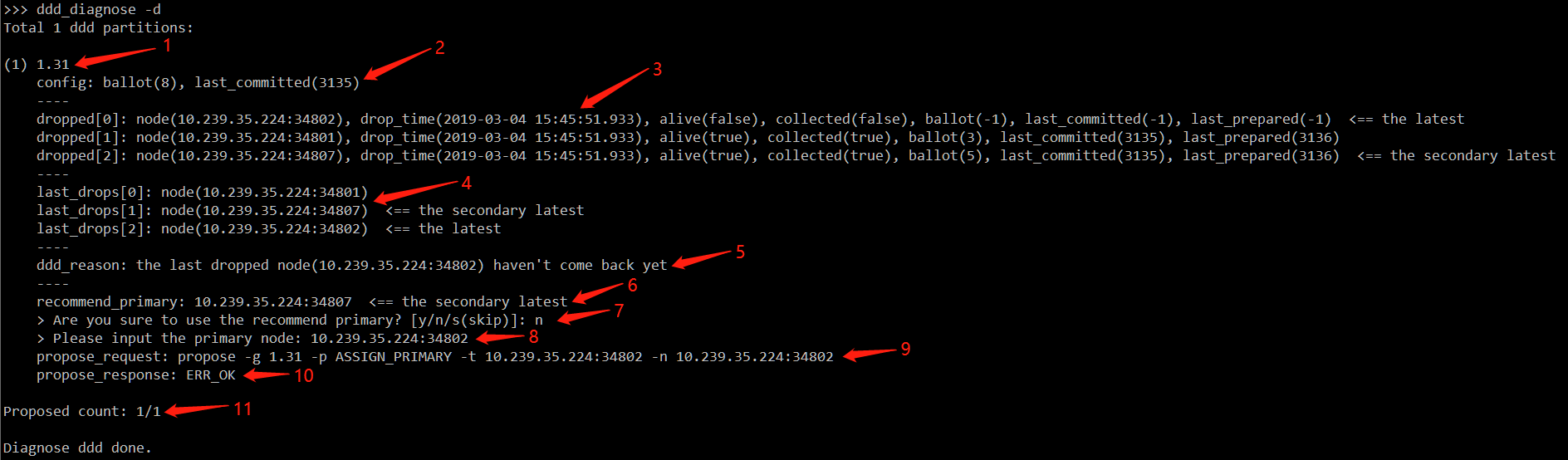
The above image is the output when using the ddd_diagnose command, and we explain it in sequence with red arrows:
-
The current partition id being diagnosed.
-
The
ballotandlast_committed_decreeinformation of this partition persisted in zookeeper, but since persistence is not real-time, this value may be less than the actual value. -
The dropped list, listing the status information of nodes that have served this partition, focusing on:
-
alive: Whether the node is available.
-
ballot: The actual
ballotof the replica on this partition on that node; if it is -1, it means that there is no data for this partition on that node. -
last_committed: The actual
last_committed_decreeof the replica on this partition on that node. -
last_prepared: The actual
last_prepared_decreeof the replica on this partition on that node. -
If there is a
<==at the end, it indicates whether the node is the latest to become unavailable or the second to last to become unavailable.
-
-
The last_drops list, recording the chronological order in which nodes become unavailable.
-
ddd_reason, indicating the reason why this partition has become a DDD state.
-
recommanded_primary, the new primary recommended by the diagnostic tool under the premise of ensuring data consistency; if it cannot be given, it is
none. -
If step 6 provides a recommended node, then prompt the user for the next step (if the
-aor-soption is specified, this step will not be entered, equivalent to always automatically selecting y):-
y: Use the recommended node as the new primary.
-
n: Do not use the recommended node and let the user choose another node.
-
s: Ignore the diagnosis of this partition.
-
-
If step 6 does not provide a recommended node or step 7 chooses n, then prompt the user to enter a new node as the primary.
-
Generate a propose command, send it to MetaServer, and designate the node as the new primary to recover this partition.
-
Receive the reply to the propose command,
ERR_OKindicates successful execution. -
Display the current progress, with the numerator being the number of diagnoses completed and the denominator being the total number of diagnoses needed.
Recommended usage:
ddd_diagnose -d -a, that is, enable automatic diagnosis, for partitions that cannot be diagnosed automatically, obtain manual intervention through interaction with the user. This is the simplest and most worry-free method, and in most cases, the recovery process can be completed automatically without manual intervention.
In cases where automatic diagnosis cannot be completed, step 8 in the above figure will be entered, requiring the user to input a new node as the primary. So, among the many nodes in the dropped list, how to choose the most suitable node as the primary? Our suggestion is:
- Among all nodes where alive is true, choose the node with the largest
last_preparedvalue, because this can recover as much data as possible and reduce the possibility of data loss.