Background Introduction
The main resources used by Pegasus include CPU, disk, memory, network, etc. The usage load of these system resources should not be too high, otherwise the Pegasus service may become unstable or even crash. It’s recommend:
- The storage usage of a single disk should not exceed 80%.
- Memory usage should not exceed 80% of each node.
- The number of network connections should not exceed the system’s limit, and it is recommended to limit the number of connections less than 50000.
By adjusting these configurations, the use of disk storage can be reduced:
- Set
max_replicas_in_group = 3, refer to Replica management. - Set
gc_disk_error_replica_interval_seconds = 3600andgc_disk_garbage_replica_interval_seconds = 3600, refer to Garbage directory management. - Set
checkpoint_reserve_min_count = 2andcheckpoint_reserve_time_seconds = 1200, refer to RocksDB checkpoints management.
Replica management
Pegasus recommends using 3 replicas (1 primary + 2 secondaries) and setting the -r parameter to 3 when creating tables.
However, the actual number of replicas in the cluster may exceed 3, which is determined by the following configuration:
[meta_server]
max_replicas_in_group = 4
The meaning of this configuration: allow the maximum number of replicas (including primary and secondaries) of a partition, with a default value of 4 (indicating allowing the retention of 1 inactive replica). Although there are 3 active replicas (1 primary + 2 secondaries) being served, during the procedure of downtime recovery or load balancing, replicas may migrate from server A to server B. After the migration, the data on server A is actually no longer needed. However, with sufficient storage, the replica on server A can be retained. If the replica is re-migrated to server A in the future, these retained replicas may be reused to avoid re-transmission.
In aim to reduce disk storage usage and delete useless replicas data in time, you can set max_replicas_in_group = 3, restart Meta Server to make the configuration take effect, and then set the Load Rebalance level to lively, allowing Meta Server to delete useless replicas data.
Garbage directory management
If the replica directory in Replica Server is no longer needed or damaged, it becomes a garbage directory: unnecessary directory has a .gar suffix, and damaged directory has a .err suffix. These directories are not deleted immediately, as they may still have value in certain extreme situations (such as recall data through them in the event of a cluster crash).
There are two configurations that determine the actual deletion time for these directories:
[replication]
gc_disk_error_replica_interval_seconds = 604800
gc_disk_garbage_replica_interval_seconds = 86400
For these two types of directories, the last modification time (before Pegasus 2.6 is the last modification time of the directory, starting from Pegasus 2.6 is the timestamp field in the directory name) of the directory will be checked, and deletion is executed when the gap between the last modification time and the current time exceeds the corresponding configuration.
In aim to reduce disk storage usage by deleting these garbage directories in time, it can be achieved by reducing the values of these two configurations.
[replication]
gc_disk_error_replica_interval_seconds = 3600
gc_disk_garbage_replica_interval_seconds = 3600
- If the Pegasus version is less than 1.11.3, it’s needed to restart the Replica Server for the configurations to take effect.
- If the Pegasus version is between 1.11.3 and 2.1, these two configurations can be modified and take effect at runtime through the
useless-dir-reserve-secondscommand in Remote commands, without restarting the Replica Server process. For example, modify these two configurations to 0 for emergency cleaning of the garbage directories:>>> remote_command -t replica-server useless-dir-reserve-seconds 0After confirming that the cleaning is complete, restore to the configurations:
>>> remote_command -t replica-server useless-dir-reserve-seconds DEFAULT - Starting from version 2.2, the configurations can be modified and take effect at runtime through the HTTP API without restarting the Replica Server process.
RocksDB checkpoints management
The storage engine of Replica Server is RocksDB, it generates checkpoint regularly. The checkpoints are placed in the data directory of the replica, and are suffixed by the last_durable_decree.
As shown in the figure below, the data directory of the replica contains the currently using rdb directory and several checkpoint directories:
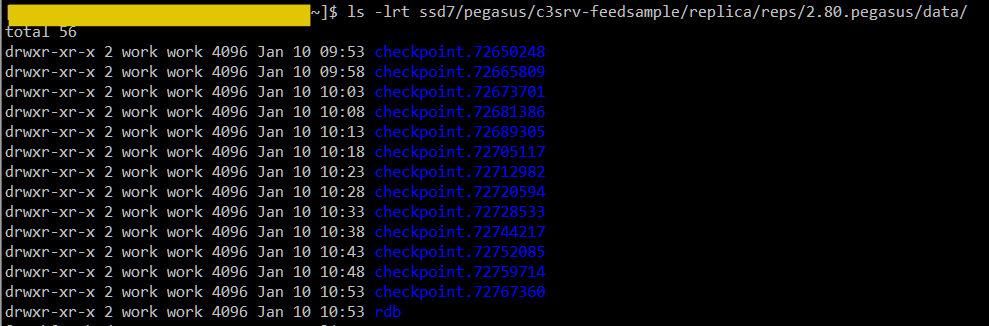
When generating a checkpoint, the files in the checkpoint are generated through hard linking rather than copying. One of the sstable files may be held by the rdb or by one or more checkpoints. As long as any one of them holds, the data of that file exists on the disk, consuming storage space. The file can be deleted only when rdb and all checkpoints do not hold it.
The RocksDB is continuously performing background compactions, so the sstable held by any checkpoint may no longer be held by rdb (call it expired). If the retention time of the checkpoints are too long, these expired sstables cannot be deleted in time, which consume extra disk storage space. Especially for tables with high write throughput, compaction occurs more frequently, and the lifecycle of a single sstable file is very short. If the number of checkpoints is kept relatively high, the storage space consumed may be several times larger than the current actual data size.
The following configurations determine the strategy for deleting checkpoints:
[pegasus.server]
checkpoint_reserve_min_count = 2
checkpoint_reserve_time_seconds = 1800
- checkpoint_reserve_min_count: represents the minimum number of reserved checkpoints. Only when the number of checkpoints exceeds this limit, the oldest checkpoint may be deleted.
- checkpoint_reserve_time_seconds: represents the minimum retention time of the checkpoint. Only when the generation time of the checkpoint exceeds this value from the current time can the oldest one be deleted.
- The checkpoint will only be deleted when meet the 2 conditions simultaneously.
In aim to reduce disk storage usage by deleting the old checkpoint directories in time, you can lower these two configurations. For example:
[pegasus.server]
checkpoint_reserve_min_count = 1
checkpoint_reserve_time_seconds = 1200
Note: It is not recommended to set checkpoint_reserve_time_seconds too low. Considering the impact on learning, it should be larger than replica_assign_delay_ms_for_dropouts (default is 5 minutes).
Set table level configuration
Since Pegasus 1.11.3, it is supported to modify these two configurations at runtime through the Table environment variable for a specified table, without restarting the Replica Server process. For example:
>>> use <table_name>
>>> set_app_envs rocksdb.checkpoint.reserve_min_count 1
>>> set_app_envs rocksdb.checkpoint.reserve_time_seconds 600