在 Pegasus 的架构中,Meta Server 是一个专门用于管理元数据的服务节点,我们在这篇文章中详细讨论它的内部机制。
MetaServer的主要功能如下:
- Table的管理
- ReplicaGroup的管理
- ReplicaServer的管理
- 集群负载的均衡
Table的管理
在Pegasus里,table相当于一个namespace,不同的table下可以有相同的(HashKey, SortKey)序对。在使用table前,需要在向MetaServer先发起建表的申请。
MetaServer在建表的时候,首先对表名以及选项做一些合法性的检查。如果检查通过,会把表的元信息持久化存储到Zookeeper上。在持久化完成后,MetaServer会为表中的每个分片都创建一条记录,叫做PartitionConfiguration。该记录里最主要的内容就是当前分片的version以及分片的composition(即Primary和Secondary分别位于哪个ReplicaServer)。
在表创建好后,一个分片的composition初始化为空。MetaServer会为空分片分配Primary和Secondary。等一个分片有一主两备后,就可以对外提供读写服务了。假如一张表所有的分片都满足一主两备份,那么这张表就是可以正常工作的。
如果用户不再需要使用一张表,可以调用删除接口对Pegasus的表进行删除。删除的信息也是先做持久化,然后再异步的将删除信息通知到各个ReplicaServer上。等所有相关ReplicaServer都得知表已经删除后,该表就变得不可访问。注意,此时数据并未作物理删除。真正的物理删除,要在一定的时间周期后发生。在此期间,假如用户想撤回删除操作,也是可以调用相关接口将表召回。这个功能称为软删除。
ReplicaGroup的管理
ReplicaGroup的管理就是上文说的对PartitionConfiguration的管理。MetaServer会对空的分片分配Primary和Secondary。随着系统中ReplicaServer的加入和移除,PartitionConfiguration中的composition也可能发生变化。其中这些变化,有可能是主动的,也可能是被动的,如:
- Primary向Secondary发送prepare消息超时,而要求踢出某个Secondary
- MetaServer通过心跳探测到某个ReplicaServer失联了,发起group变更
- 因为一些负载均衡的需求,Primary可能会主动发生降级,以进行迁移
发生ReplicaGroup成员变更的原因不一而足,这里不再一一列举。但总的来说,成员的每一次变更,都会在MetaServer这里进行记录,每次变更所引发的PartitionConfiguration变化,也都会由MetaServer进行持久化。
值得说明的是,和很多Raft系的存储系统(Kudu、TiKV)不同,Pegasus的MetaServer并非group成员变更的见证者,而是持有者。在前者的实现中,group的成员变更是由group本生发起,并先在group内部做持久化,之后再异步通知给MetaServer。
而在Pegasus中,group的状态变化都是先在MetaServer上发生的,然后再在group的成员之间得以体现。哪怕是一个Primary想要踢出一个Secondary, 也要先向MetaServer发起申请;等MetaServer“登记在案”后,这个变更才会在Primary上生效。
ReplicaServer的管理
当一台ReplicaServer上线时,它会首先向MetaServer进行注册。注册成功后,MetaServer会指定一些Replica让该Server进行服务。
在ReplicaServer和MetaServer都正常运行时,ReplicaServer会定期向MetaServer发送心跳消息,来确保在MetaServer端自己“活着”。当MetaServer检测到ReplicaServer的心跳断掉后,会把这台机器标记为下线并尝试对受影响的ReplicaGroup做调整。这一过程,我们叫做FailureDetector。
当前的FailureDetector是按照PacificA中描述的算法来实现的。主要的改动有两点:
- PacificA中要求FailureDetector在ReplicaGroup中的Primary和Secondary之间实施,而Pegasus在MetaServer和ReplicaServer之间实施。
- 因为MetaServer的服务是采用主备模式保证高可用的,所以我们对论文中的算法做了些强化:即FailureDetector的双方是ReplicaServer和“主备MetaServer组成的group”。这样的做法,可以使得FD可以对抗单个MetaServer的不可用。
算法的细节不再展开,这里简述下算法所蕴含的几个设计原则:
-
所有的ReplicaServer无条件服从MetaServer
当MetaServer认为ReplicaServer不可用时,并不会再借助其他外界信息来做进一步确认。为了更进一步说明问题,考虑以下情况:
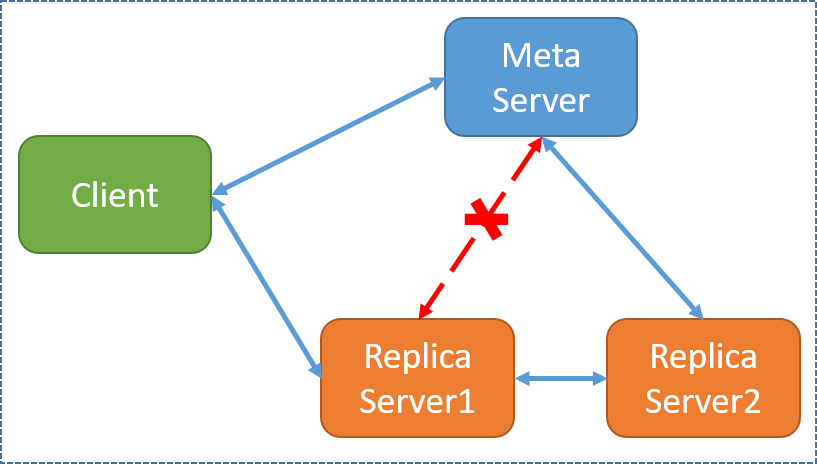 上图给出了一种比较诡异的网络分区情况:即网络中所有其他的组件都可以正常连通,只有MetaServer和一台ReplicaServer发生了网络分区。在这种情况下,仅仅把ReplicaServer的生死交给MetaServer来仲裁可能略显武断。但考虑到这种情况其实极其罕见,并且就简化系统设计出发,我们认为这样处理并无不妥。而且假如我们不开上帝视角的话,判断一个“crash”是不是“真的crash”本身就是非常困难的事情。
上图给出了一种比较诡异的网络分区情况:即网络中所有其他的组件都可以正常连通,只有MetaServer和一台ReplicaServer发生了网络分区。在这种情况下,仅仅把ReplicaServer的生死交给MetaServer来仲裁可能略显武断。但考虑到这种情况其实极其罕见,并且就简化系统设计出发,我们认为这样处理并无不妥。而且假如我们不开上帝视角的话,判断一个“crash”是不是“真的crash”本身就是非常困难的事情。与此相对应的是另外一种情况:假如ReplicaServer因为一些原因发生了写流程的阻塞(磁盘阻塞,写线程死锁),而心跳则由于在另外的线程中得以向MetaServer正常发送。这种情况当前Pegasus是无法处理的。一般来说,应对这种问题的方法还是要在server的写线程里引入心跳,后续Pegasus可以在这方面跟进。
-
Pefect Failure Detector
当MetaServer声称一个ReplicaServer不可用时,该ReplicaServer一定要处于不可服务的状态。这一点是由算法本身来保障的。之所以要有这一要求,是为了防止系统中某个ReplicaGroup可能会出现双主的局面。
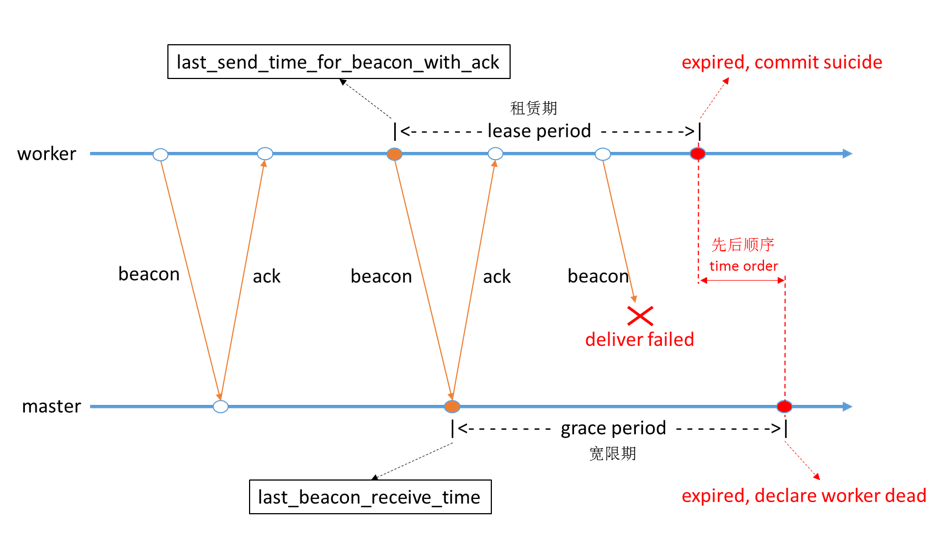
Pegasus使用基于租约的心跳机制来进行失败检测,其原理如下(以下的worker对应ReplicaServer, master对应MetaServer):
 说明:
说明:- beacon总是从worker发送给master,发送间隔为beacon_interval
- 对于worker,超时时间为lease_period
- 对于master,超时时间为grace_period
- 通常来说:grace_period > lease_period > beacon_interval * 2
以上租约机制还可以用租房子来进行比喻:
- 在租房过程中涉及到两种角色:租户和房东。租户的目标就是成为房子的primary(获得对房子的使用权);房东的原则是保证同一时刻只有一个租户拥有对房子的使用权(避免一房多租)。
- 租户定期向房东交租金,以获取对房子的使用权。如果要一直住下去,就要不停地续租。租户交租金有个习惯,就是每次总是交到距离交租金当天以后固定天数(lease period)为止。但是由于一些原因,并不是每次都能成功将租金交给房东(譬如找不到房东了或者转账失败了)。租户从最后一次成功交租金的那天(last send time with ack)开始算时间,当发现租金所覆盖的天数达到了(lease timeout),就知道房子到期了,会自觉搬出去。
- 房东从最后一次成功收到租户交来的租金那天开始算时间,当发现房子到期了却还没有收到续租的租金,就会考虑新找租户了。当然房东人比较好,会给租户几天宽限期(grace period)。如果从上次收到租金时间(last beacon receive time)到现在超过了宽限期,就会让新的租户搬进去。由于此时租户已经自觉搬出去了,就不会出现两个租户同时去住一个房子的尴尬情况。
- 所以上面两个时间:lease period和grace period,后者总是大于前者。
集群的负载均衡
在Pegasus里,集群的负载均衡主要由两方面组成:
-
cure: 如果某个ReplicaGroup不满足主备条件了,该如何处理
简单来说:
- 如果一个ReplicaGroup中缺少Primary, MetaServer会选择一个Secondary提名为新的Primary;
- 如果ReplicaGroup中缺Secondary,MetaServer会根据负载选一个合适的Secondary;
- 如果备份太多,MetaServer会根据负载选一个删除。
-
balancer: 分片如果在ReplicaServer上分布不均衡,该怎么调节
当前Pegasus在做ReplicaServer的均衡时,考虑的因素包括:
- 每个ReplicaServer的各个磁盘上的Replica的个数
- Primary和Secondary分开考虑
- 各个表分开考虑
- 如果可以通过做Primary切换来调匀,则优先做Primary切换。
具体的balancer算法,我们会用专门的章节来进行介绍。
MetaServer的高可用
为了保证MetaServer本身不会成为系统的单点,MetaServer依赖Zookeeper做了高可用。在具体的实现上,我们主要使用了Zookeeper节点的ephemeral和sequence特性来封装了一个分布式锁。该锁可以保证同一时刻只有一个MetaServer作为leader而提供服务;如果leader不可用,某个follower会收到通知而成为新的leader。
为了保证MetaServer的leader和follower能拥有一致的集群元数据,元数据的持久化我们也是通过Zookeeper来完成的。
我们使用了Zookeeper官方的c语言库来访问Zookeeper集群。因为其没有提供CMakeLists的构建方式,所以目前这部分代码是单独抽取了出来的。后面重构我们的构建过程后,应该可以把这个依赖去掉而直接用原生代码。
MetaServer的bootstrap
当一个MetaServer的进程启动时,它会首先根据配置好的zookeeper服务的路径,来检测自己是否能够成为leader。如果是leader, 它会向zookeeper拉去当前集群的所有元数据,包括:
- 有哪些表,以及这些表的各种参数
- 每个表的各个Partition的组成情况,将所有Partition中涉及到的机器求并集,会顺便解析到一个机器列表
当MetaServer获取了所有的这些信息后,会构建自己的内存数据结构。特别的,ReplicaServer的集合初始化为2中得到的机器列表。
随后,MetaServer开启FD的模块和负载均衡的模块,MetaServer就启动完成了。